本記事はアイドルマスター Advent Calendar 2019 12月19日の記事です。
おはようございます。たくみP(imas_cg集計 @shuukei_imas_cg)です。担当はシンデレラガールズの喜多日菜子です。
今回はアイマス関連Webサービスのバックエンドに関するテクニカルなテーマで、アイマス成分はほとんどありません。その代わり今年のアドベントカレンダーでは喜多日菜子 Advent Calendar 2019に日菜子の「むふふ」のバリエーションとその頻度分布を投稿しておりますのでご興味があればご覧ください。
はじめに
Google Cloud Runは任意のDockerコンテナをアップロードしてサーバレスで実行し使った分だけ課金される、つまり言語やミドルウェアに一切の制限がない非常に汎用性の高いサービスです。2019年9月頃に東京リージョンでのベータサービスが開始し、先日、11月28日にGA(正式サービス)となりました。
(コンテナの使い方としては少し邪道かもしれませんが)サービスを構成する複数のミドルウェアを1個のコンテナに全部突っ込んでまとめれば、あとはGoogleのインフラが全部面倒見てくれる、しかも無料枠付きで一定ラインまでは無料で使える便利サービスなわけです。
が、Qiitaなどの技術系投稿サイトを見た感じ、”Hello World!”レベルのごく小規模な事例しか見当たらなかったので、形態素解析器MeCabとその辞書(NEologd)を含む比較的大きなコンテナ(2GB~)をCloud Runに乗せて、その使用感を試したいと思います(というか、この記事を書いている時点ですでに本番環境で利用してしまっています)。
「台詞判定」サービスとは
2017年2月9日にサービスインした、「任意の台詞テキストを入力すると、アイドルの誰の台詞っぽいか判定してくれる」Webサービスです。シンデレラガールズ台詞判定など実物を触っていただくか、筆者のSpeaker Deckの「シンデレラガールズの台詞のみから「誰の台詞か」機械学習で判定する」「シンデレラガールズ台詞判定の開発・運用・反響について」のスライドを見ていただくのが手っ取り早いです。
フロントエンドはVue.jsで構築してあり、サーバとHTTPSで通信します。サーバサイドではテキストを入力として受け取り、アイドル名とスコア(それらしさ)のリストをJSON形式で出力します。いわゆるSPAです。
サーバレス化のモチベーション
公開直後は最大で同時500アクセスもあったこのサービスも、2年も経つとアクセスも散発的になってきます。そのためにVPSなり自宅サーバなりを動かし続けるのは不経済ですし、1台のサーバに複数のREST APIを相乗りさせてNginxでルーティング…みたいなことをやると、いずれかのサービスのメンテナンスが他のサービスに波及して面倒くさくなります。いわゆるマイクロサービス的に分割して、1サービス1個のHTTPSエンドポイントを提供できれば、メンテナンス性は大幅に向上し、小規模なサービスであればCloud Runの無料枠の範囲に収まってお財布にも優しくなります。
従来のサーバサイドの構成
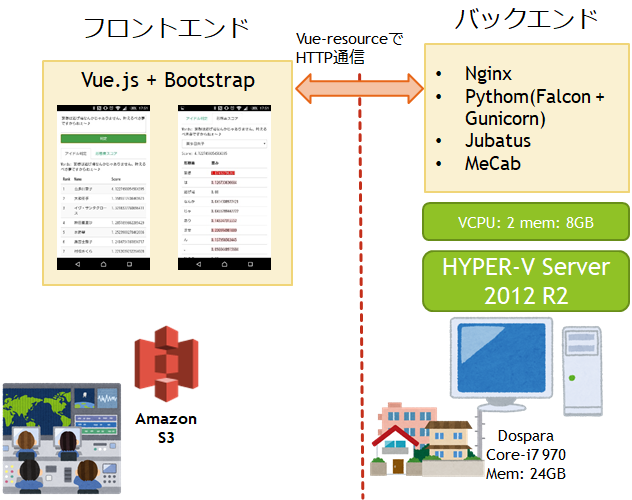
年代物のPCに仮想化ハイパーバイザとしてHYPER-V Server 2012R2をセットアップし、その上でCentOS 6系の仮想マシンが動いています。
HTTPリクエストはリバースプロキシのNginxが受け取り、Python用のWebサーバとフレームワークが処理します。
さらに裏では機械学習フレームワークのJubatusが動いており、入力された台詞テキストから「最もその台詞を発したアイドルらしい」アイドルを推薦します。
形態素解析には定番のMeCabを、新語辞書としてmecab-ipadic-NEologdを、追加で自作のアイマス人名辞書を使用しています。
サーバレスサービスというとGCPならCloud Functions、AWSならLambdaが有名ですが、これらのサービスは基本的に単一のプログラミング言語で書けるロジックを扱うものなので、yumやaptでMeCabやJubatusをインストールしたり、NEologdを追加して使うことはできません。
Dockerコンテナ化
そこでDockerコンテナなら何でも扱えるCloud Runの出番です。まずは既存のサーバサイドをコンテナ化しましょう。
戦略
- 機械学習のtrainは事前に手元のVMで行い、保存した機械学習モデルのファイルをコンテナにコピーする。
- NEologdはコンテナ化対象のWORKDIR以下にパスを指定してインストールし、コンテナに含める。
- ./bin/install-mecab-ipadic-neologd -n -a -y -p インストール先パス
- 自作のMeCabユーザ辞書も同様。
- ログはあまり真面目に取らない
この時点でDockerのWORKDIRのサイズは以下の通り。/mecab の中身はNEologdとユーザ辞書です。./ に100MBほどのファイルがありますが、これはプログラム本体と、機械学習モデルファイル、「形態素スコア」機能で使用している形態素ごとのアイドルらしさの重みを記録したファイルからなります。
1 | $ du -h |
プログラム本体はhttps://github.com/shuukei-imas-cg/imas_cg_wordsにサブセットを公開していますので参考にしてください。
プログラムの改修
VM上で動かしていたプログラムをコンテナに乗せるにあたり、1点だけ、これまでファイルに記録していたログを標準出力に出力するよう変更しました(Pythonのloggingモジュールを使っていれば、ほんの1行書き換えるだけで済みます)。コンテナは不変なので、仮にコンテナ内のファイルにログを取っても、コンテナが再起動すれば消えてしまうからです。
Cloud Runで動作するコンテナの挙動、具体的には標準出力の内容とHTTPアクセスのログは当該GCPプロジェクトのStackdriver Loggingで確認できるので、それで最低限のログの確認はできます。
もし、ちゃんと構造化したログ取りが必要であれば、Stackdriver Logging クライアント ライブラリを用い、リクエストの内容を別途ロギングするのが良いと思います。それをBigQueryにエクスポートするよう設定したり、そこまで大袈裟でなくてもいいなら、Cloud Storageにエクスポートしてgcloudコマンドでローカルにダウンロードして分析するのが手軽かなと思われます。
Dockerfile
Dockerfileは以下のような内容になりました。
1 | FROM ubuntu:18.10 |
このサービスは制作時期の関係もあってPython2.7系で作っています。ベースイメージをPython:2.7にしようかと思ったのですが、Jubatusインストール時のrequirementをうまく満たせなかったので、素のubuntuからpythonを入れています。そのためビルドにはかなり時間がかかり、コンテナサイズも大きくなりがちです。もう少し改良の余地がありそうです(ベースイメージの選択やマルチステージビルドの導入など)。
startup.shの中身はJubatus用の環境変数設定とjubaclassifier(Jubatusの分類器バイナリ)の起動、gunicorn(Webサーバ)の起動です。Dockerコンテナ内で複数のプロセスを起動する場合、シェルスクリプトを書いてそれをDockerfileのCMDコマンドで起動する手法を取ります。
1 | #!/usr/bin/env bash |
コンテナのビルドと実行
コンテナをビルドします。
1 | $ docker build -t serif-predict . |
2.56GB。うっ、でかい……。NEologdを全部入り(-aオプション)でインストールしているのでなおさら大きいです。とりあえず実行してみます。
1 | docker run -e PORT=8008 -p 8008:8008 asia.gcr.io/imas-api-serve/serif-predict |
docker statsで確認すると、MEM USAGE / LIMITは1.064GiB / 7.777GiBでした。ギリギリ1GBに収まらないくらいです。
Cloud Runでサーブする
デプロイ
まず、GoogleのコンテナリポジトリサービスであるGoogle Container Registryに先程のコンテナをアップロードします(GCPプロジェクト”imas-api-serve”を事前に作成しているものとする)。
1 | docker tag serif-predict asia.gcr.io/imas-api-serve/serif-predict |
Cloud Runを使うための細かい解説は他に譲ります。プロジェクトでCloud Runを有効化し、課金アカウントを割り当てます。ここで注意すべきは、無料枠の範囲で使いたい、そのくらいしか使わないよ、という場合でも、課金アカウント(クレジットカード)の割り当ては必須であることです。
Cloud Runの管理画面から「サービスを作成」を選び、先程pushしたコンテナを選んでリージョン(ここではasia-northeast1:東京)やサービス名を設定します。1つのGCPプロジェクトに複数のCloud Runサービスを作成できます。
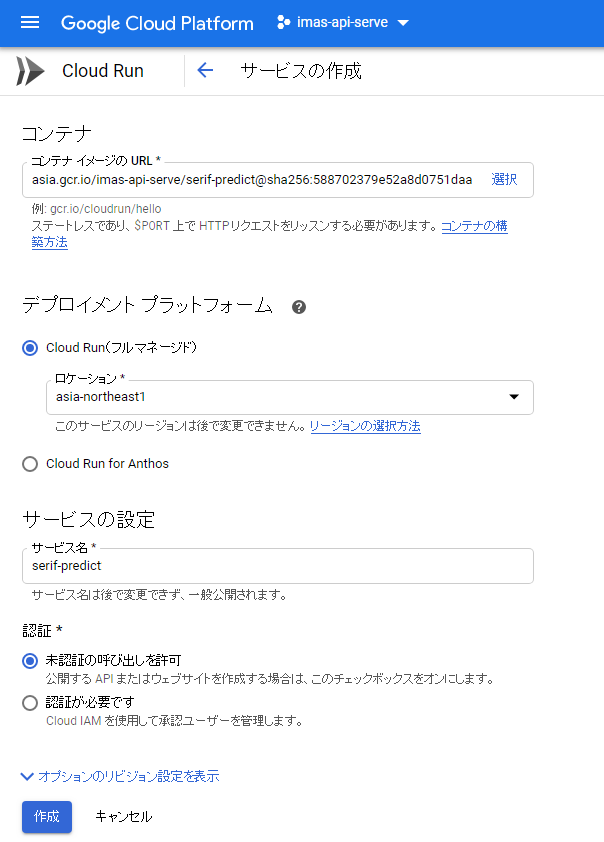
メモリはデフォルトでは256MiBしか割り当てられないので、「オプションのリビジョン設定を表示」から設定する必要があります(最大2GiBまで)。今回はMaxの2GiBを指定しました。
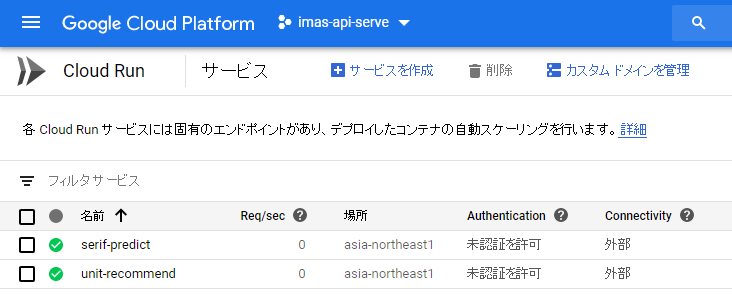
サービスが作成されました。各サービスには固有のHTTPSエンドポイント(“サービス名”-“ランダムな文字列”-an.a.run.app/ みたいなURL)が割り当てられます。
https://serif-predict-2zvjww2i3q-an.a.run.app/imas_cg-words/v1/predict/妄想ぱわーのように直接URLを叩いてみると、正しく結果が返っているようです。
あとは、フロントエンドのコードを書き換えてWebAPIのリクエスト先をこちらに変更してしまえば移行完了です。
使用量
2019-11月の一ヶ月分について請求書を確認したことろ、CPU Allocation Timeは1,258.5 vCPU秒/月、Memory Allocation Timeは2,300 GiB/月でした。docker statsコマンドで消費メモリを確認したとき1GBちょっとでしたので、1GB * 約1300秒 = 約1300GB・秒になりそうなものですが、スピンアップ時に一時的にもっとメモリを使っているのかもしれません。
また、コンテナを保存するためにCloud Storageを1GiB弱使っています。
いずれにせよ無料枠は180,000vCPU 秒/月・360,000GiB/月なので、__Cloud Runについては__余裕で収まる範囲です。が、上述のCloud Storage分で3円ほどかかりました。
参考: Cloud Run
無料枠に関する考察
「180,000vCPU 秒/月・360,000GiB/月・200万リクエスト/月」という無料枠についてもう少し考察してみます。
今回のサービスでは、1回のリクエストにかかるサーバサイドの処理時間は入力テキストの長さに応じて25ms~800msと幅がありますが、ログをざっと観察して、平均して250ms程度と仮定します。100ms単位で切り上げなので300ms vCPUの処理時間が課金されます。
18万秒 ÷ 30日 = 6000秒/日 = 600万ミリ秒/日
6000000ms ÷ 300ms/req = 20000req
となり、1日2万リクエストを受け入れられます。実際には1つのインスタンスで複数のリクエストを受け入れられるのでもっと余裕がありますが、ここではアクセスは散発的であるとし、同時に使おうとするユーザは1人だけと仮定しました。
リクエストあたりのメモリ使用量は、実測値2300GiBと1258.5秒からするとその比率は1.83となり、2倍には届かないことから、18万秒フルに使用しても36万GiBを超えることはありません。
また、200万リクエスト/月 = 66666リクエスト/日 ですから、リクエスト数の無料枠を超えることもなさそうです。
もしAPIのレスポンスサイズが大きい場合は、これらとは別にネットワーク転送量枠を考慮する必要がありますが、今回のサービスではその必要はありません。
使用感
実行時間は100ms単位でカウントされ、使用されない間はまったく料金がかからないのがCloud Runの利点ですが、停止状態からのスピンアップにはそれなりの時間がかかります。今回の例では7~10sほどかかっており、UX的にちょっとどうなのという感じです(フロントエンド側で起動中であることを示す仕組みが必要)。
このスピンアップの処理がローカルVMのDockerで”docker run”した場合とまったく同等なのか不明ですが、ローカルVMでは4~5s程度で完了できるので、それに比べるといくらか遅いです。
反面、一度スピンアップしてしまえばローカル環境と同程度のレスポンスで使えます(文章量により20ms~800ms程度)。
従って、しばらくアクセスがなくてコンテナが停止している場合の最初の1回のスピンアップだけなんとか待ってもらえば、以降は同等の感覚で使ってもらえそうです。
まとめ
フロントエンドはSPAなので静的HTMLが置けるサービスであればどこでもよく、サーバサイドもサーバレスにできたので、サーバのお守りから開放されました。
継続して提供はしたいがアクセス数はそれほどでもないサービスを無料または低価格で提供する方法としても使えるのではないでしょうか。これまで、そうした用途にはHerokuやGoogle App Engine(Standard Environment)の無料枠を利用する方法が定番とされてきましたが、任意のコンテナが使えるCloud Runにはそれらを大きく凌駕する汎用性があります。
注意点としては、WebAPIとしてサーブする関係上「未認証の呼び出しを許可」に設定して、一切の認証を行っていないので、DoSアタックされるとクラウド破産しかねないことがあります。事前に料金の上限アラートを設定しておく必要があるでしょう。